
Learnings from a Machine Learning Engineer — Part 2: The Data Sets
Welcome back to our journey into the heart of Artificial Intelligence, where we demystify the complex and illuminate the practical. In this second installment of our series, we delve into the lifeblood of machine learning: the data sets. Whether you’re a technology enthusiast, a business professional, a curious student, or simply an intrigued reader, this article is crafted to guide you through the intricacies of AI data sets with clarity and simplicity.
Understanding the Foundation
At its core, machine learning is about teaching computers to learn from data. But not all data is created equal. Here, we explore the types of data sets that power AI, their characteristics, and why they’re pivotal for developing intelligent systems.
The Significance of Quality Data
Discover why the quality of data sets is crucial for the success of AI projects. We’ll break down the common challenges and share insights on how to overcome them, ensuring your AI can learn effectively.
- Types of data sets and their impact on learning outcomes
- Strategies for improving data quality
- Real-world examples of data set challenges and solutions
Applications Across Industries
AI’s reach extends far into various sectors. We’ll showcase how different industries leverage data sets to drive innovation, from healthcare’s predictive analytics to finance’s risk assessment models and education’s personalized learning experiences.
Preparing for the Future
As we look ahead, the evolution of data sets and machine learning techniques promises to revolutionize how we interact with technology. We’ll ponder the future implications and how you can stay ahead in the rapidly changing landscape of AI.
Join us as we continue to unravel the mysteries of machine learning, making the complex accessible and the cutting-edge understandable. Our exploration of data sets is not just about understanding AI; it’s about envisioning its potential to transform our world.
This introduction sets the stage for a comprehensive exploration of data sets in the context of machine learning, aiming to educate and engage a broad audience. The use of HTML formatting, including unnumbered lists and bold text, enhances readability and emphasizes key points, while the structured sections promise a clear and informative journey through the topic.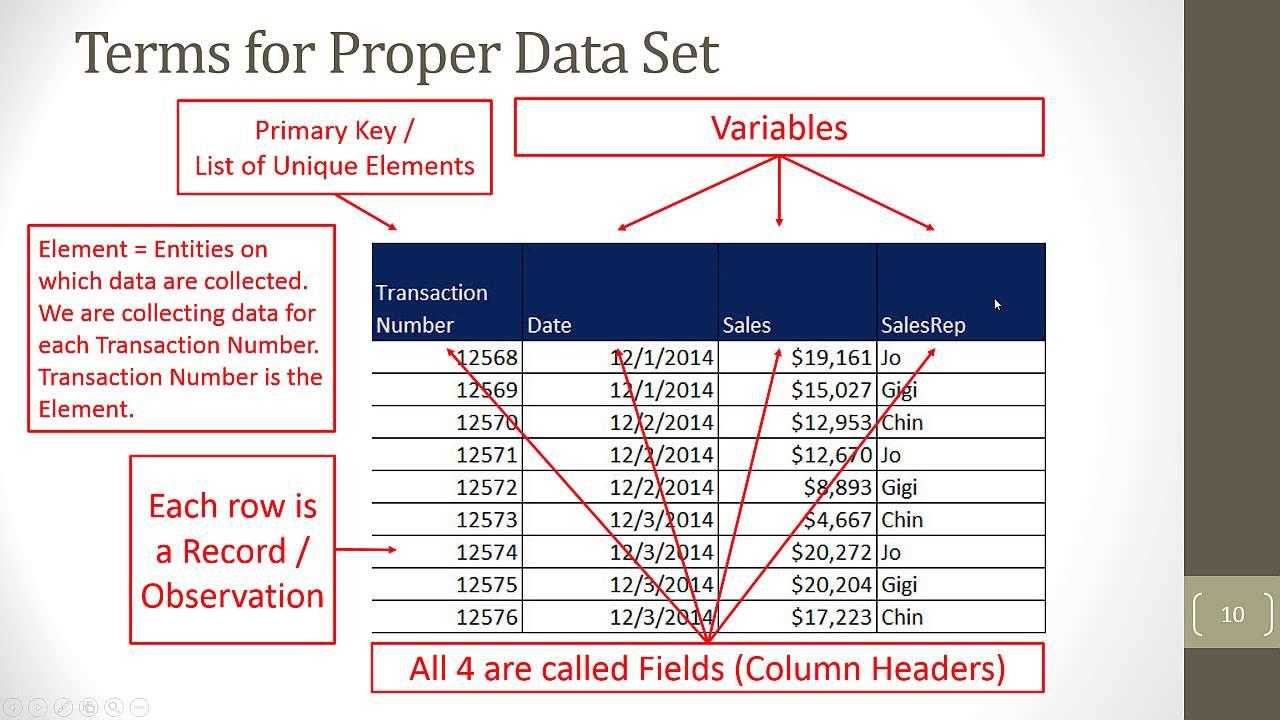
– Unveiling the Mysteries of Data Sets: What They Are and Why They Matter
In the realm of Artificial Intelligence, data sets are akin to the fuel that powers the engines of machine learning models. Imagine trying to teach a child to recognize different fruits without ever showing them an apple or a banana. This is precisely the challenge AI faces without access to diverse and comprehensive data sets. These collections of data can come in various forms, from rows of numbers representing financial transactions to images labeled to identify objects. They serve as the foundational building blocks that allow AI to learn, adapt, and eventually make predictions or decisions based on new, unseen information.
Why do these data sets matter so much? The answer lies in the quality and variety of the data they contain. A well-curated data set can significantly enhance the performance of an AI model, enabling it to understand complex patterns and nuances. For instance, in healthcare, data sets comprising patient records, treatment outcomes, and genetic information can help develop models that predict diseases earlier and with greater accuracy. However, it’s crucial to ensure these data sets are balanced and unbiased, as any inherent biases can lead to skewed AI decisions. Below is a simple table illustrating types of data sets and their potential applications:
| Type of Data Set | Potential Application |
|---|---|
| Image Data Sets | Facial recognition, autonomous vehicles |
| Text Data Sets | Natural language processing, chatbots |
| Numerical Data Sets | Financial forecasting, risk assessment |
| Audio Data Sets | Speech recognition, music recommendation |
Understanding the significance of data sets not only demystifies how AI models learn but also highlights the importance of ethical considerations in AI development. By ensuring data sets are comprehensive, diverse, and free from biases, we pave the way for AI technologies that are fair, effective, and capable of transforming industries in ways that benefit everyone.
– The Art of Data Cleaning: Techniques for Pristine Data Sets
In the realm of machine learning, the quality of your data sets can make or break your models. Before a single algorithm learns its first pattern, the data it’s fed needs to be as clean and accurate as possible. This is where the art of data cleaning comes into play, a crucial step often overlooked in the rush to results. Data cleaning involves several techniques aimed at identifying and correcting inaccuracies, filling in missing values, and smoothing out noise in your data. These steps ensure that the data sets are pristine, which in turn, enhances the performance of machine learning models.
To start, let’s explore some common techniques used in the data cleaning process:
- Removing duplicates: This step is essential to prevent the model from being biased towards repeated entries.
- Handling missing values: Options include imputing missing values based on other data points or removing rows with missing values altogether, depending on the scenario and data set size.
- Normalizing data: Ensuring that numerical inputs fall within a similar range so that models don’t become skewed by the scale of features.
- Encoding categorical variables: Transforming non-numerical labels into numerical codes, allowing algorithms to understand and leverage this data.
| Technique | Description | Impact on Model |
|---|---|---|
| Removing duplicates | Eliminates repeated data entries | Reduces bias |
| Handling missing values | Imputes or removes data points with missing information | Improves accuracy |
| Normalizing data | Adjusts numerical scales to a uniform range | Prevents skewness |
| Encoding categorical variables | Converts labels into numerical codes | Enables algorithm comprehension |
By meticulously applying these techniques, data scientists can significantly enhance the reliability and performance of their machine learning models. It’s a testament to the fact that in the world of AI, the devil truly is in the details. The process of data cleaning might not be glamorous, but its impact on the outcomes of AI projects cannot be overstated. As we continue to push the boundaries of what machine learning can achieve, the foundation of pristine data sets remains a cornerstone of success.
– From Raw Data to Insights: The Journey of Data Transformation
The transformation of raw data into actionable insights is akin to finding a needle in a haystack, but with the right tools and techniques, it becomes an exhilarating treasure hunt. At the heart of this process is data preprocessing, a critical step that involves cleaning, normalizing, and transforming data to improve its quality and usefulness for machine learning models. This stage can significantly influence the accuracy and efficiency of predictive analytics, making it essential for machine learning engineers to master. Techniques such as handling missing values, encoding categorical variables, and feature scaling are employed to ensure that the dataset is well-suited for the algorithms that will analyze it.
Following preprocessing, the journey continues with data exploration and visualization. This phase allows engineers and data scientists to uncover patterns, anomalies, and correlations within the data that may not be immediately apparent. Tools like Python’s Matplotlib and Seaborn libraries come into play, offering a wide range of plotting functions to create clear and informative visual representations of the data. For instance, scatter plots can reveal relationships between variables, while histograms provide insights into the distribution of data points. Through these visual explorations, valuable insights are gleaned, guiding the development of more effective machine learning models.
| Step | Description | Tools/Techniques |
|---|---|---|
| 1. Data Cleaning | Removing duplicates, handling missing values | Pandas, NumPy |
| 2. Feature Engineering | Creating new variables to improve model’s performance | Scikit-learn |
| 3. Data Visualization | Identifying patterns and relationships | Matplotlib, Seaborn |
Through this meticulous process of transforming raw data into a structured and meaningful format, machine learning engineers pave the way for generating actionable insights that can drive decision-making and innovation across industries. By understanding and applying these fundamental steps, anyone interested in AI can begin to appreciate the complexity and power of machine learning in extracting value from data.
– The Ethical Dimensions of Data: Navigating Privacy and Bias
In the realm of artificial intelligence, the data we feed into our algorithms holds the power to shape outcomes in profound ways. It’s a double-edged sword; on one hand, comprehensive data sets can enable AI systems to make more accurate predictions and decisions, enhancing efficiency and innovation across industries. On the other hand, these data sets can also harbor biases and infringe on privacy, leading to ethical dilemmas that demand careful navigation. Privacy concerns arise when personal data is collected, often without explicit consent, and used to train AI models. This raises questions about surveillance, data ownership, and the potential for misuse of sensitive information. To mitigate these risks, it’s crucial to implement robust data anonymization techniques and establish clear data governance policies that prioritize individual rights.
Bias in AI, meanwhile, is a reflection of the biases present in the data itself. Whether it’s gender, racial, or socioeconomic biases, these prejudices can lead to unfair outcomes, such as discriminatory hiring practices or biased law enforcement predictions. Addressing bias requires a multifaceted approach:
- Diversifying data sources to ensure a wide range of perspectives and experiences are represented.
- Implementing fairness algorithms that can detect and correct for biases in the data.
- Encouraging transparency by making AI systems’ decision-making processes more understandable and open to scrutiny.
| Challenge | Strategy |
|---|---|
| Data Privacy | Implement data anonymization and governance policies |
| Data Bias | Diversify data sources and use fairness algorithms |
By conscientiously addressing these ethical dimensions, we can steer the development of AI technologies towards more equitable and respectful use of data. This not only enhances the societal benefits of AI but also builds trust in these technologies, ensuring they are used responsibly and for the greater good.
Concluding Remarks
As we wrap up the second part of our journey through the eyes of a machine learning engineer, it’s clear that the road to mastering AI is both fascinating and complex. The datasets we’ve explored are not just collections of numbers and categories; they are the very foundation upon which the towering structures of artificial intelligence are built. They tell stories, reveal patterns, and unlock the potential for transformative innovations across every sector imaginable.
Key Takeaways:
- Understanding Data: The essence of AI’s power lies in its ability to learn from data. The quality, diversity, and relevance of the datasets are crucial for developing robust and effective AI models.
- Ethical Considerations: As we delve deeper into the world of AI, the ethical implications of data collection, privacy, and bias become increasingly important. It’s our responsibility to ensure that AI technologies are developed and used in a way that benefits society as a whole.
- Practical Applications: From healthcare diagnostics to personalized education plans, the applications of AI are as varied as they are impactful. By harnessing the power of data, we can solve complex problems and improve lives.
Looking Ahead:
The journey through the world of AI is ongoing, and the landscape is constantly evolving. As we continue to explore new technologies, techniques, and applications, the possibilities are limitless. Whether you’re a business professional seeking to leverage AI for competitive advantage, a student eager to dive into the world of machine learning, or simply a curious mind fascinated by the potential of artificial intelligence, there’s always more to learn and discover.
Engage and Explore:
We encourage you to engage with the material, ask questions, and explore the vast universe of AI. The future is being written in lines of code and datasets, and you have the opportunity to be a part of that exciting narrative. Stay tuned for more insights, stories, and explorations into the world of artificial intelligence.
As we conclude “Learnings from a Machine Learning Engineer — Part 2: The Data Sets,” we hope you leave with a deeper understanding of the critical role data plays in AI and feel inspired to explore how AI can be applied in your own life or work. The journey of discovery in AI is endless, and each step forward opens new doors to innovation, understanding, and potential.
Thank you for joining us on this adventure. The future of AI is bright, and together, we can navigate its complexities, celebrate its achievements, and contribute to its responsible growth and development.